Эволюция моделей
Чтобы вы могли принять решение или совершить действие, нужна модель. Мозг создаёт их всегда: как мы говорили – мышление и есть моделирование. Поэтому когда мы действуем, мы опираемся на какую-то модель. Чаще всего это будут не специально/сознательно созданные модели, а их первые версии. Когда мы действуем с опорой на модель неоднократно, она постепенно достраивается и превращается в продвинутую, хорошо прокритикованную модель с четкими причинно-следственными связями.
На старте у нас есть первая версия модели/принципиальное представление о теме, например, модель принятия решения о сотрудничестве с клиентом или модель запуска проекта. Она обычно составлена как-нибудь, очень приблизительно и неточно, часто без применения специальных методов, а чисто кустарно. И это правильно, ведь на старте важнее появление хоть какой-нибудь более-менее подходящей модели, с опорой на которую можно принимать решения. Чтобы такую модель можно было признать «достаточно хорошей», в ней не должно быть грубых ошибок, приводящих к гарантированно неправильным решениям, она должна сподвигать на действие и помогать дальше уточнять и корректировать действия и последующие версии модели. Если вы создали первую версию модели, то можно проверить её, если задать следующие вопросы: «Что точно будет неправильным действием в данной ситуации (например, действия, гарантированно разрушающие бизнес, вроде конфликтов со всеми клиентами, точно не приведут к его развитию)?», «Модель помогает перейти к действию побыстрее и начать проверку предположений, стоящих за ней, в жизни?», «После проверки моделей действием можем ли мы сказать, что узнали что-то новое и смогли сделать шаг в нужном направлении?». Если на все три вопроса ответ «да», то первая версия модели полезна, и её стоит развивать. Если нет, стоит вернуться и переработать её.
Поэтому шаг первый – получить «примерную модель в нужном направлении» и затем перейти к действию на её основе, а затем уточнять модель столько раз, сколько потребуется. Это эволюционный аргумент в моделировании. С точки зрения эволюции, на старте важнее скорость, а не точность: пока у вас нет никакой модели (или никакой формы жизни), вам нечего развивать/дорабатывать. Поэтому на старте надо максимально быстро получить неправильную, но полезную первую версию модели, например, модели завершения проекта. После чего её начнут критиковать и корректировать – и это очень хорошо, потому что критика и корректировки – сигнал, что работа в нужном направлении идёт. До этого она вообще стояла, потому что ни у кого не было представления о том, что и как делать. Первая модель часто получаем за счёт (полу)бездумного копирования имеющихся удачных моделей, «методом обезьянки»: «смотри на меня и делай как я».
После получения модели её желательно как можно быстрее начать тестировать – за счёт того, что вы принимаете (для начала не самые важные) решения на её основе и затем корректируете модель. Например, если вы хотите провести изменения в работе команд, то начинаете менять методы работы в тех командах или на тех проектах команд, где это не принесёт большого ущерба. Если вносите изменения в продукт, например, добавляете новый функционал в приложение, то сначала тестируете на небольшой выборке. Вам надо проверить как вашу модель, так и находящиеся «под капотом» неявные предположения, на основе которых вы моделировали. Например, вам предлагается прописать планы развития сотрудников. Неявно предполагается, что развитие любых сотрудников – это всегда хорошо, и любое повышение квалификации в мастерстве любого сотрудника поможет компании. Однако это может быть не так: если вы – компания, которая продаёт труд своих сотрудников (работает на аутсорсе), то вам может быть невыгодно выращивать слишком много супер-профессионалов: либо придётся им много платить (и у компании не сойдется бизнес-модель, она будет работать в убыток), либо смириться с тем, что наиболее квалифицированные, на обучение которых затрачено больше всего сил, уходят. Соответственно, надо прописать предположения: как следует обучать/развивать ваших сотрудников, чтобы не увеличивать отток самых квалифицированных, а затем протестировать предположения экспериментом.
После первых тестов необходимо вернуться к модели и откорректировать её. Теперь точность становится (постепенно) важнее скорости. Здесь первая версия модели, дающая принципиальное представление о предмете, начинает становиться более точной: часто агент ещё не применяет никакой метод для её изменения целенаправленно, просто нащупывает предположения и «как-то» их тестирует. На данной стадии важно не упустить, какие именно объекты вы выделяете как важные для модели, какие – как неважные, почему, по вашему мнению, предположения при тестировании оказались не соответствующими/соответствующими тому, как вещи работают в реальности. Здесь обычно начинают уточнять имеющиеся описания, применяя знания моделирования явно. При создании первой версии модели вы, скорее всего, лишь примерно выделили объекты и определили роль(и) и ролевые способы описания/способы смотреть на мир/рассмотрения/viewpoints, предметные области. Здесь всё это нужно уточнять. Значительная часть предположений, которые вы будете проверять в следующих экспериментах, всё ещё будут найденными интуитивно/ассоциативно, поэтому такая модель называется ассоциативной; но небольшая часть предположений уже будет базироваться на более строгих/формальных рациональных рассуждениях, и их доля дальше будет расти.
На следующей стадии ваша модель продолжит усложняться. В какой-то момент её сложность будет такой, что передать другим модель (объяснить так, чтобы поняли и смогли применять) станет без специальных разъяснений невозможно. Тогда можно считать, что первая версия модели развилась в другую – продвинутую. Продвинутая модель по другой классификации относится еще к разделяющаим/классифицирующим/discriminative моделям, что означает, что в ней применяется явная классификация объектов (используется хорошая онтология для составления модели). Разделяющая модель будет получаться за счёт более строгого контроля типов и простраивания реальных причинно-следственных связей. Например, выполняя задания по организации работ в команде, вы можете обнаружить, что реальный выпуск вашей команды или компании совсем не такой, как вы думали – а также реальное ограничение не там, где вы ожидали. Вы можете управлять контентной командой и считать, что ограничением команды как создателя являются редакторы – а потом проверить и обнаружить, что в данный момент это рабочая станция «корректоры», потому что корректор у вас остался один и работает медленнее редакторов. Ваша модель работы команды усложняется, вы понимаете, как именно изменения в количестве сотрудников и работы влияют на выпуск кейсов команды.
Разделяющие модели, например, разделяющая модель работы команды, будет позволять вам как менеджеру/управленцу проводить вмешательства точно там, где надо. Однако если вам потребуется передать другому модель во всей её сложности, то это будет не так просто. И тогда на помощь вам придёт принципиальная модель.
Принципиальная модель – это модель, которая очень упрощённо демонстрирует наиболее важные объекты внимания и причинно-следственные связи. Например, принципиальная модель предприятия будет содержать описание ключевых методов, применяемых на предприятии. Модель Demand-Stock-Production (DSP), которую вы видели ранее, можно отнести к принципиальным моделям.
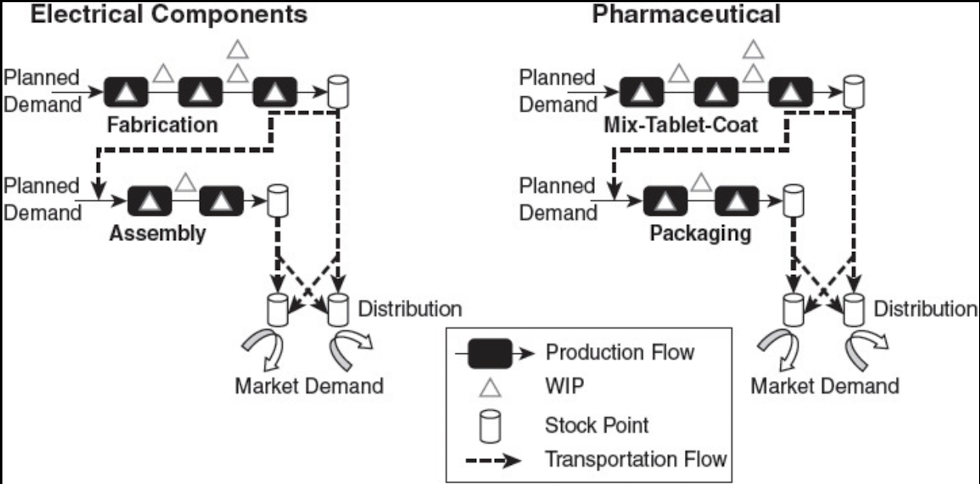
СхемыDemand*-Stock-*Production для производства электронных компонентов и лекарств
Важно в ней следующее: она показывает наиболее важные объекты, которые должны быть во внимании тех, кто занимается данной предметной областью. При этом показывает она их упрощённо, чтобы дать принципиальное представление об объектах. Она даёт первое понимание/обработку идеи в мозгах («скелет»), на которое уже можно наращивать «мясо» – детализации и уточнения. Например, модель DSP нужна для того, чтобы объяснить даже далёкому от вашей отрасли адресату, чем занимается ваше предприятие и какие ключевые методы применяются на производственных линиях вашего предприятия. При этом модель не даст понимания, как на самом деле выполняются работы по этим методам; не покажет текущее количество незавершёнки/WIP на предприятии. Кроме того, она провоцирует неправильное понимание работ, поэтому даже в какой-то мере неверна. Если вы посмотрите на эту модель, то вы можете посчитать, что работы на предприятии идут строго последовательно, по водопаду: – но это не так! Нельзя сказать, что на заводе, производящем лекарства, сначала только смешиваются вещества для будущих таблеток, затем создаётся форма, в которую заливается смесь, и наконец, таблетка покрывается внешним слоем, а затем упаковывается в блистер. Конечно, в реальности смесь могут замешать, а потом обнаружить, что её надо поправить, и вернуть на доработку. Вот эта реальная траектория движения реальных таблеток по предприятию на принципиальной схеме и не отражена. Поэтому нельзя сказать, что она показывает, как будут двигаться реальные партии таблеток по конвейеру (реальная траектория будет сложнее), но можно сказать, что она даёт представление о том, работы по каким методам не имеют никакого смысла до тех пор, пока не предприняты попытки провести работы по другим методам. Например, пока у вас нет ни одной попытки получить таблетку, нет никакого смысла заниматься упаковкой: вам банально нечего упаковать в блистер. Вот поэтому модель полезна: она даёт первое представление о том, как рассуждать о путешествии вещи по конвейеру и позволяет начать разговор о реальных работах. При этом такая модель не первая версия: она не появляется, чтобы заполнить пустое место и начать разговор, а появляется после того, как появились разделяющие модели, и служит как посредник при передаче разделяющей модели другим, например, вашим сотрудникам. По сути, принципиальная модель выступает каркасом, на котором будет наращиваться «мясо» – более сложные модели и развёртки.
При составлении разделяющих моделей вы столкнётесь с сопротивлением доучиванию. Научиться периодически контролировать типы относительно несложно; включить машинку типов в голове так, чтобы она работала бесперебойно и не выключалась уже сложнее. На пути вы столкнётесь как с проблемами в удержании внимания, описанными в разделе «Удержать внимание на сменах состояний объектов», так и с сопротивлением доучиванию. Контроль типов и составление разделяющих моделей требует ресурсов – в первую очередь задействования вычислительных ресурсов мозга и ваших электронных вычислителей. Вычислительный ресурс мозга ограничен, его легко потратить впустую, в результате чего качественная модель не будет составлена. При пересборке сложных онтологий много времени придётся потратить как на поиск удачных решений, так и на последующее переучивание себя и окружающих думать и принимать решения по-новому постоянно. По сути, придётся учиться менять метод мышления/modus operandi: нужно буквально забыть, как вы думали раньше.
Если вы уже дошли до той стадии развития мастерства, когда вы можете примерно типизировать, но проваливаетесь в сложных ситуациях, или можете включить контроль типов, составить формальную модель или пересобрать сложную онтологию, но вспоминаете об этом лишь иногда, нужно доучивание себя (и окружающих). Доучивание удобно проводить на небольших высказываниях. Например, попробуйте проконтролировать типы в отправленных в рабочие чаты сообщениях, в ваших последних постах в клуб МИМ. Какие ошибки вы найдете? Какие ошибки повторяются довольно часто (те где именно слетает контроль типов)? Если вы работаете с визуальными схемами, включите пункт «проверить типы» в описание метода/алгоритм метода составления и/или проверки такой схемы. Проверку типов можно включить в описание методов выполнения и других задач. Всё это позволит быстрее автоматизировать навык контролировать типы в устной и письменной речи.