Использование буферов для компенсации изменчивости
Пока предприятие будет работать, на нём и вокруг него всегда будет что-то меняться. Будут приходить и уходить клиенты, сотрудники; будут меняться приоритеты менеджмента, законодательство, по которому работает компания. И даже акты выполнения работ квалифицированным сотрудником по хорошо известному методу не будут одинаковы: в один день работу можно будет выполнить легко и быстро, а в другой кто-то забудет предоставить информацию (и её надо будет добыть), отвалится Интернет, в середине работы заболит зуб и так далее. Поэтому акты выполнения работ будут уникальными, отличающимися друг от друга, что повлияет на загрузку, скорость и время выполнения. Иными словами, работа предприятия как конвейера характеризуется **изменчивостью/**variability.
Изменчивость как математическая величина – это мера неодинаковости объектов в классе. Например, возьмём двери, произведённые на одном предприятии. Если мы замерим длину, ширину и высоту с точностью до миллиметра или даже больше, то почти наверняка окажется, что параметры не совпадают точь-в-точь, а немного отличаются. Мы можем посчитать, насколько отличаются параметры, и затем вычислить, укладываются ли они в допустимые отклонения/допуски по производственному стандарту – ГОСТ 475-2016 «Блоки дверные деревянные и комбинированные» (1-3 мм для дверных блоков разных размеров). Если параметры изменяются очень мало и укладываются в допустимые отклонения, это говорит о качественно налаженном производстве таких дверей.
Работа по методу может демонстрировать отклонения от «среднего» по разным причинам. По шкале случайности(слева)-предсказуемости(справа) причины отклонений могут быть очень предсказуемыми. Так, например, если вы даёте задачи сотрудникам, но не планируете сразу же задачу по контролю сделанного (не обязательно вами), то появившаяся внезапно для вас необходимость проверить рабочий продукт и внеплановая задача, повлиявшая на вашу нагрузку как рабочей станции, на самом деле, конечно, не была внезапной. Поэтому то, что для вас как операционного менеджера (наблюдателя в физике) выглядело случайностью, ею не было: внезапной эта задача была из-за пропущенного менеджерского действия и/или отсутствия знания, что такое действие надо выполнить. Задания в разделе «Различать метод и работу» были нацелены на выявление задач, пропущенных из-за отсутствия внимания к ним или знания, что их надо выполнять. Выведение таких задач из класса «скрытых» в класс «явно планируемых» позволяет инженерам-менеджерам повысить предсказуемость нагрузки (например, с 50% плановых – 50% внеплановых до 75% плановых – 25% внеплановых или даже 85% плановых – 15% внеплановых).
С другой стороны, что-то может происходить абсолютно случайно: вы как операционный менеджер не могли предусмотреть заранее проблемы. Например, вы не можете предсказать заранее обрыв проводов и отключение света в офисе, но это тоже повлияет на сроки выполнения работ. Чем выше ваше мастерство как операционного менеджера, тем меньше будет случайностей, которые вы не могли предусмотреть (но они всё равно останутся!), тем более экзотическими будут эти случайности. То есть, по мере прироста знаний вы будете передвигаться вправо по шкале случайности-предсказуемости. То же самое верно для любой другой роли.
Изменчивость будет тем выше, чем больше в работе неопределённости. На производственных предприятиях, производящих типовую продукцию, степень неопределённости результатов куда ниже, чем у компаний, ориентированных на интеллектуальный труд и производящих продукцию при помощи не станков, но мозгов своих сотрудников. Когда вы делаете межкомнатные двери, вы можете пойти и пощупать уже произведённые экземпляры из предыдущих партий, посмотреть ГОСТы, описывающие стандарты для производства, составить достаточно точные модели и менять их нечасто. Когда вы делаете двери на заказ, у вас увеличивается неопределённость: теперь конвейер должен быть готов гибко подстраиваться под параметры, например, производить очень высокие двери для домов с потолками 3+ метра, соответственно, потребуется больше переналадок оборудования, подготовки сотрудников и так далее. Но есть предприятия как конвейеры, которые создают продукты, почти целиком зависящие от качества интеллекта сотрудников, то есть, качества куска мозга/белкового вычислителя сотрудника, обученного решать проблемы, которые ранее не решал как минимум он, как максимум никто другой. Степень изменчивости процессов таких конвейеров выше. Это повлияет на загрузку станций и на то, какое сочетание буферов придётся использовать. То есть, изменчивость предприятия-как-конвейера/рабочей станции/производственной линии у компаний одного типа будет выше относительно компаний другого типа, и это зависит от стратегических выборов компании.
Изменчивость станции и изменчивость линий/потоков/flows cвязаны между собой. С одной стороны, каждая отдельная станция вносит в производственную линию дополнительные изменения: она может выйти из строя, уйти в отпуск (если это человек), просто не очень работать и так далее, что увеличивает её потоковое время/время выполнения работ. Соответственно, следующая после неё станция получит рабочий продукт/результат выполнения работ чуть позже, т.е. внесёт дополнительную изменчивость в процесс. С другой – она получила рабочие продукты «на входе». Вот эта скорость входа объектов или задач, или arrival rate, будет «потоковой изменчивостью», внешней по отношению к отдельной станции. Эта скорость входа объектов или задач, как вы помните, является переменной для расчёта загрузки станции:
Загрузка станции = скорость входа объектов или задач (arrivalrate**)** / производственная мощность станции
То есть, на загрузку станции будет влиять её собственная изменчивость (отклонения от предельной скорости выпуска станции), а также накопленные до неё отклонения (изменчивость линий/потоков, то есть, flow variability). С методами расчёта изменчивости и учёта их при планировании работ вы можете познакомиться в соответствующей литературе (крайне рекомендуется): Factory Physics, Wallace J. Hopp, Mark L. Spearman; Supply Chain Management, Wallace J. Hopp. На данный момент важно само понимание физического смысла изменчивости и того, как её наличие влияет на выпуск.
Изменчивость приводит к уменьшению выпуска по сравнению с ситуацией, когда части конвейера всегда работают стабильно, на предельной скорости, без каких-либо проблем. Это затрудняет прогнозы сроков выпуска. К счастью, изменчивость можно компенсировать/смягчить при помощи буферов.
Буфер – специальный объект в операционном менеджменте, который позволяет смягчить влияние изменчивости на выпуск. Буферы бывают 3 типов:
- Буфер товарно-материальных запасов/inventory, когда объект в состоянии «готов» (или «частично готов») появляется до того, как предъявлен спрос на него (считаем товар «предзаказанным»/backordered), то есть, товар ждёт заказа;
- Буфер времени, когда спрос на товары или услуги (заказ) ждёт, пока не будет произведён товар;
- Буфер ресурсов/производственной мощности, который уменьшает потребность в двух других типах буферов.
Буфер товарно-материальных запасов обычно есть у компаний, производящих товары, а не предоставляющих услуги. Например, можно запасти готовые автомобили или готовые полуфабрикаты, но нельзя запасти обработанные раны в травматологии. Однако мы можем говорить, например, о том, чтобы запасти побольше готовых статей (т.е. средств прибавки мастерства у клиентов), но не публиковать их пока, а поставить на отложенную публикацию или вовсе отложить в запас на случай, если эксперты не смогут вовремя выдать другой актуальный материал (то есть, в процессе работы экспертов проявится изменчивость). Вам нужно будет подумать, возможно ли иметь в вашей производственной линии такой буфер; если вы не работаете с поставкой товаров, то он может не быть нужным. Например, статьи «в складских запасах» имеют свойство быстро устаревать; поэтому расходы на создание такого буфера могут быть больше, чем выгода от его наличия, и проще сосредоточиться на двух других типах буферов.
Если для вашей компании буферы товарно-материальных запасов имеют смысл (например, вы производите ленточные конвейеры для шахт) и/или вы решите его поддерживать (например, писать статьи «про запас»), то нужно будет при помощи экспериментов найти оптимальные места размещения таких буферов и требуемое количество предварительной подготовки. Вы можете выбрать поддерживать небольшой запас «готовой продукции» на складе, как это делает, например, «Макдональдс»: популярные/ходовые продукты, например, картошку, готовят «про запас» и складывают на подогреваемые подносы, откуда картошку можно быстро насыпать в упаковку для клиента, что позволяет компании поддерживать высокую скорость доставки/delivery для клиента – одно из выбранных компанией стратегических преимуществ, которое поддерживается операционным решением по размещению буфера. В ресторанах «Бургер Кинга» пошли по другому пути: чтобы отличаться от «Макдональдса», сосредоточились на предоставлении клиенту более широкого выбора и возможностей «персонализировать»/кастомизировать заказ под себя. Этот стратегический выбор привёл к тому, что «Бургер Кингу» пришлось отказаться от политики поддержки запаса готовых гамбургеров: во-первых, неизвестно, закажет ли такой гамбургер клиент, или предпочтёт «кастомизировать» даже ходовую позицию; во-вторых, поскольку продуктовая линейка шире, пришлось бы поддерживать более большой запас готовой продукции питания – а она быстро портится. Поэтому приходится собирать гамбургеры из частей на ходу. Чтобы при этом не слишком замедлять выдачу заказов, «Бургер Кинг» увеличил размер буфера другого типа – буфера «производственной мощности».
**Буфер производственной мощности/**capacity– второй тип буферов, который часто недоиспользуется. Менеджеры часто озабочены «эффективностью использования ресурсов компании» и делают не то, что нужно для повышения прибыли, а то, что видно / легко контролировать – «режут косты». Стараются уменьшить размеры и количество рабочих станций (например, команд) и загрузить их на 100%, чтобы «отрабатывали зарплату». Однако это неправильная политика, потому что она… увеличивает время выполнения работ/Flow Time вместо того, чтобы уменьшать его! Более того, чем выше изменчивость процессов, тем больше растянутся сроки выполнения! Вы уже наблюдали это на графике зависимости времени выполнения от загрузки станции/capacity utilization:
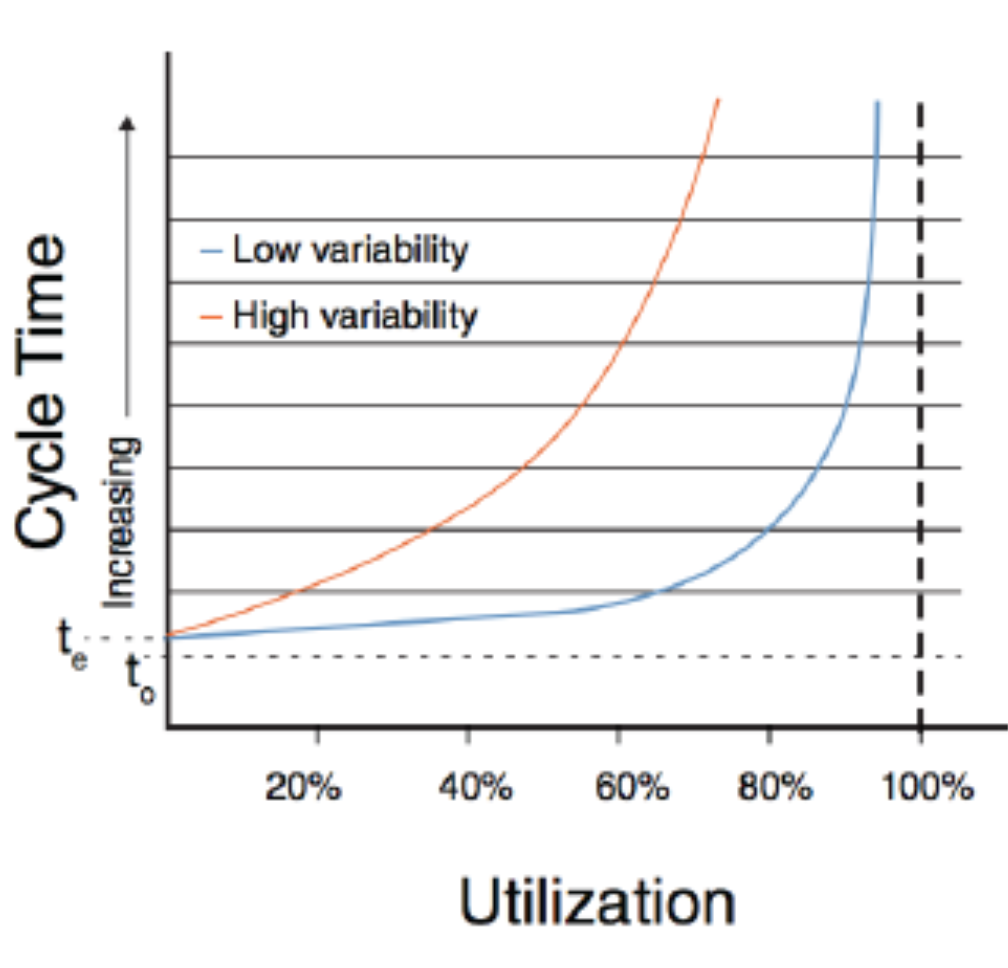
При низкой изменчивости оптимальная загрузка станций (кроме ограничения) плановой работой обычно колеблется в диапазоне 60-80% и после достижения 80% начинает резко расти. В проектах с высокой изменчивостью (где регулярно приходится менять список задач) оптимальная загрузка станций находится в диапазоне 40-60% (!) и начинает очень резко расти после 60%. Почему так происходит? Дело в том, что изменчивость больше всего влияет не на компонент времени касания/Touch Time как составляющей потокового времени/Flow Time, а на компонент времени ожидания/Wait Time (Flow Time = Touch Time + Wait Time). Для рабочих станций, которые не ограничивают накапливание «незавершенки», время ожидания/Wait Time считается так:
Wait****Time = Variability * Utilization * Time
Время ожидания = коэффициент вариаци****и (входящая**) * загрузка станции * эффективное время обработки/effectiveprocess****time**
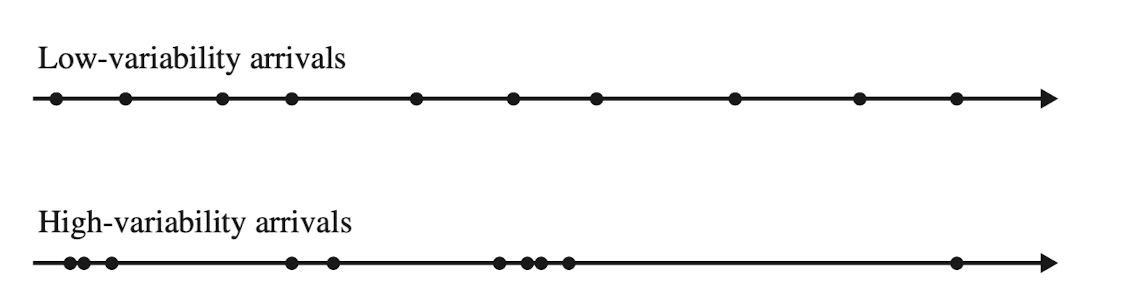
Коэффициент вариации в данном уравнении оценивает изменчивость входящего потока: как часто рабочая станция получает «на вход» (в очередь) новые предметы работ/work items (приоритетные, не те, что лежат в бэклоге) и как меняется время между приходами:
Загрузка станции в данном уравнении – это показатель загрузки, рассчитанный ранее продемонстрированным методом.
Наконец, время или эффективное время обработки**/effectiveprocess****time**в данном уравнении – это время от события «предмет работ попал в начало (верх) очереди» (перед ним никаких предметов работ нет) и до события «завершения работ над предметом работ» (или «предмет работ передан следующей рабочей станции и от неё не получены доделки»). Например, для автора это время от момента, когда одна статья ушла редактору, но вторая еще не взята в работу, потому что не поступил сигнал (ушедшая статья ещё не «одобрена к публикации») и до события «вторая статья одобрена к публикации».
Как видите, чисто математически время ожидания увеличивается, если коэффициент вариации высокий (те изменчивость сильная). Чтобы эту изменчивость компенсировать, надо уменьшать загрузку (это действие доступно операционному менеджеру) или менять методы работы, из-за чего уменьшится эффективное время обработки (это действие доступно исполнителям других менеджерских ролей, например, методологу, лидеру).
Если операционный менеджер хочет получить максимальную скорость выпуска/Throughput/Throughput Rate, то нужно платить за избыточные производственные мощности и недогружать их. Тогда у вас появляется возможность компенсировать резкие изменения. Какие есть способы реализовать этот буфер, например, в компаниях, ориентированных на интеллектуальный труд: вы нанимаете (на регулярной основе или непостоянно) чуть больше людей, чем вам нужно. Например, в периоды высокой нагрузки привлекаете фрилансеров, доплачиваете сотрудникам за работу по выходным. Можно автоматизировать выполнение типовых операций, чтобы ваша рабочая станция была не человеком или группой людей, а машиной; платить за дополнительный машинный ресурс в долгосрочном периоде выгоднее, чем за дополнительный человеческий. Ещё один способ – повышать кросс-функциональность, т.е. тренировать сотрудников на выполнение работ по ранее не знакомым им методам. Допустим, ваши разработчики обычно не занимаются тестированием, но могут (в случае перегруза тестировщиков) написать простенькие автотесты. В случае если выпуск ограничен рабочей станцией, работающей по методу тестирования, вы можете попросить часть ваших разработчиков исполнить роли тестировщиков, и это может быть выгоднее, чем ждать, пока тестировщики справятся с нагрузкой. Даже несмотря на то, что временные тестировщики будут менее опытными, они могут выполнить часть работ, а остаток (проверку/контроль и исправление ошибок) будет провести быстрее, и релиз выйдет на неделю раньше, чем если бы разработчики не переключились на другую роль (не перешли временно в рабочую станцию тестирования). Кроме того, типовые сценарии тестирования может и вовсе выполнить ChatGPT[1], это оказывается выгоднее[2]. Вы можете увеличить производственную мощность рабочей станции (а также буфер производственной мощности) за счет нейросетей относительно недорого.
Буфер времени – самый популярный/часто используемый буфер. В случае если менеджер не выбирает сознательно доплатить за «лишний» ресурс или сделать запасы, то изменчивость будет компенсироваться только увеличением времени исполнения, хотите вы того или нет. Этот закон физики предприятия называется «Заплати сейчас или плати потом» / PayMeNoworPayMeLater: если вы не выберете сознательно какую-то комбинацию буферов и не заплатите за неё, то вы будете платить позже одним или несколькими последствиями:
- Потерей выпуска,
- Увеличением сроков / времени выполнения работ,
- Увеличением запасов поверх необходимого,
- Потерей производственной мощности,
- Ухудшением клиентского обслуживания.
Ресурсы всегда ограничены, части предприятия и путешествующие через них объекты подчиняются законам физики. Даже если вы или ваше начальство очень хотите, вы не сможете их нарушать регулярно. Человек может выпрыгнуть из окна 9 этажа и остаться живым – но заплатит за это ухудшением здоровья; а если он начнёт прыгать регулярно, это приведёт его к закономерному итогу очень быстро. Если менеджеры компании регулярно игнорируют законы физики предприятия (на которых основаны практики/методы операционного менеджмента), компанию тоже ждёт закономерный и предсказуемый итог.
В случае использования буфера времени ждать будет клиент/заказчик: сроки исполнения заказа увеличиваются.
В TameFlow, который описывает операционный менеджмент для компаний, ориентированных на интеллектуальный труд (knowledge work), все три типа буферов присутствуют, но описаны немного по-другому.
Во-первых, есть буфер типа «Барабан-Буфер-Канат»/буфер ББК/Drum-Buffer-RopeBuffer**/DBRBuffer**. Это аналог буфера товарно-материальных запасов, предназначенный для того, чтобы ваше ограничение (самое медленное из бутылочных горлышек), которое, собственно, ограничивает выпуск, работало на максимуме (близко к 100% загрузке – это единственная из рабочих станций, которая может работать с такой загрузкой). Буфер ББК позволяет обеспечить стабильность выпуска: ограничение работает бесперебойно. Достигается это за счёт того, что команды начинают пользоваться усовершенствованными версиями Канбан-досок[3] – досками «Барабан-Буфер-Канат»[4]:
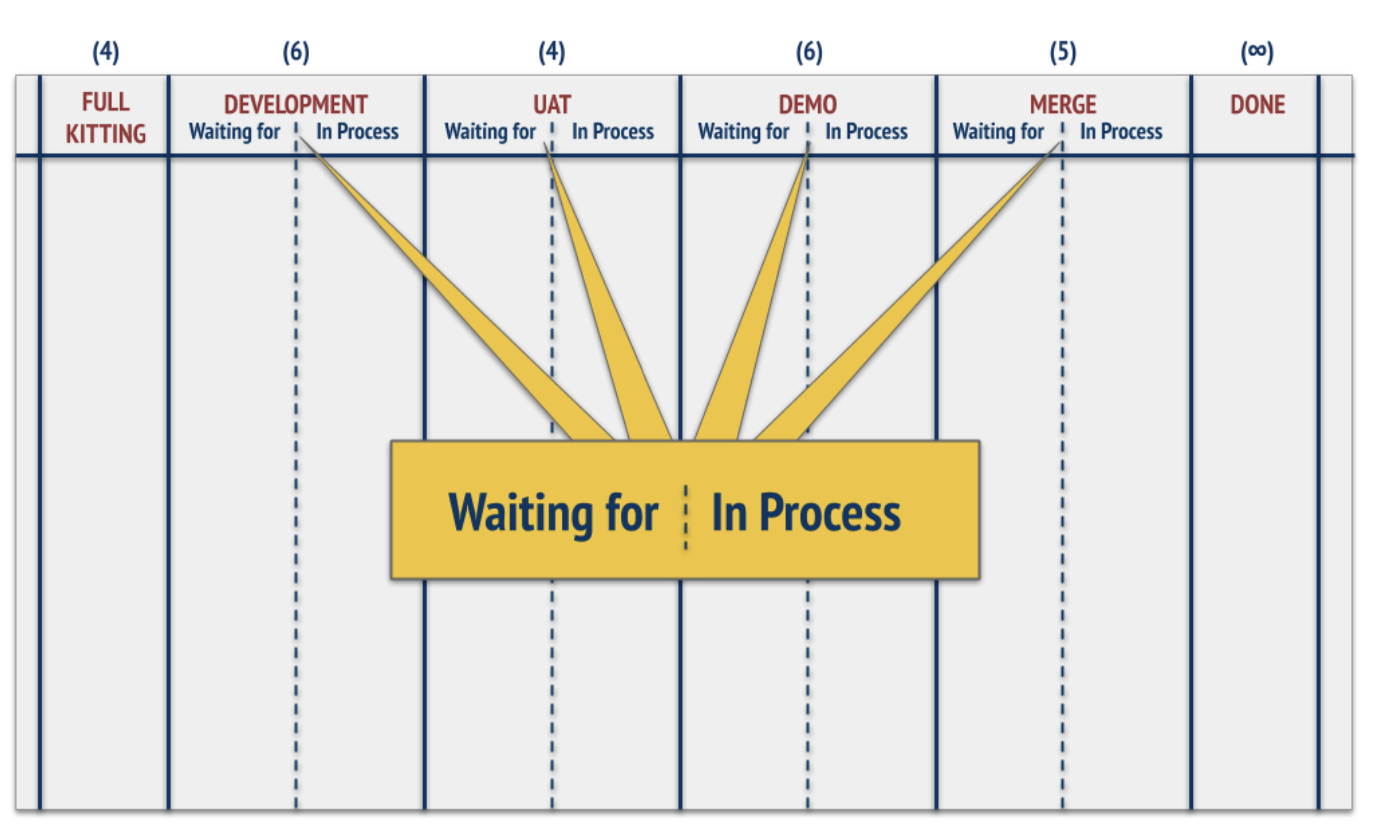
Бэклог задач не показан на картинке. В бэклоге лежат все задачи, над которыми планируется когда-либо поработать. Для релиза отбирается какое-то фич и багфиксов, которые будут выпущены в релизе, в бэклоге представлены задачи, которые описывают необходимые работы по получению этих фич и исправленных багов. Этот отобранный набор готовится к работе (проводится предварительная подготовка/Full Kitting): продумывается, что именно пойдет в работу, нужно ли ещё что-то сделать, чтобы задачу можно было взять в работу, и так далее. Отобранные задачи попадают в колонку «Full Kitting» и в дальнейшем выполняются.
В названиях колонок отражено название методов работ рабочих станций, через которые пройдут отобранные задачи (development, user acceptance testing/UAT и так далее). Каждый метод соответствует какой-то рабочей станции, выполняющей работы по этому методу: например, «разработка» – это метод, выполняемый рабочей станцией «разработчики команды Х». Мы можем рассчитать время, в течение которого одна задача путешествует по всей доске. А можем рассчитать среднее время/Average Flow Time, которое задача проводит в одной колонке (соответствующей какой-то рабочей станции). Мы можем рассчитать среднее время задачи в колонке/Average Flow Time и посмотреть, где оно будет максимальным – это и есть самая медленная рабочая станция в рамках команды[5]. Перед ней нужно создать буфер задач: перед этой станцией всегда должна быть очередь задач на выполнение, она не должна ждать работу. Если эта станция будет ждать, это закончится потерей выпуска команды (а если эта команда ограничивает выпуск предприятия, то будет потеря выпуска предприятия). Если у вас контентная команда, то вы соответственно ищете ограничение внутри неё. Допустим, что это автор – тогда у автора должна быть очередь из одобренных / согласованных тем для статей (темы для статей как предметы работ прошли предварительную подготовку/Full Kitting: отобраны и согласованы), чтобы автор, получив сигнал (например, сигнал об одобрении статьи), смог сразу взять в работу следующую статью.
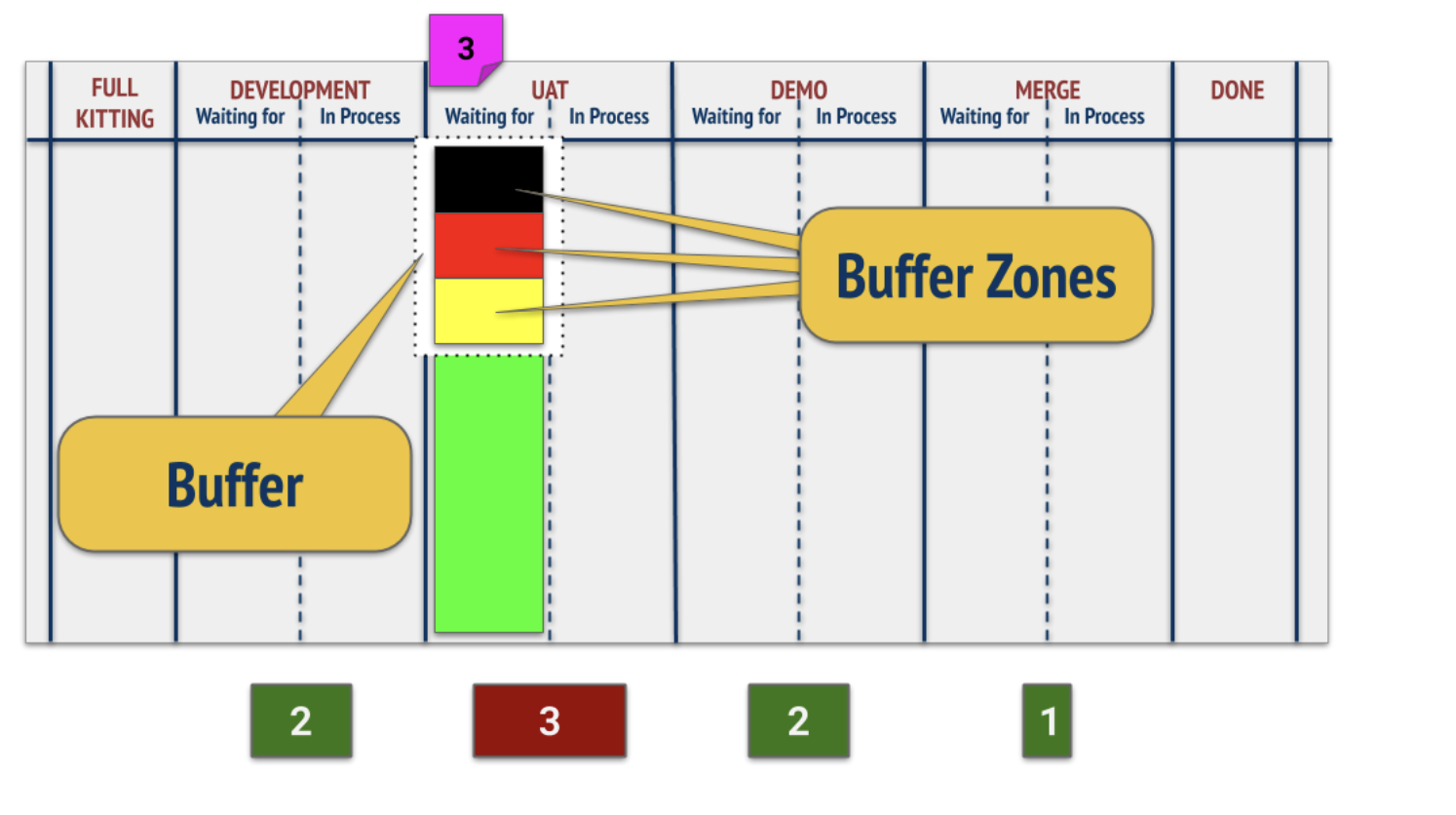
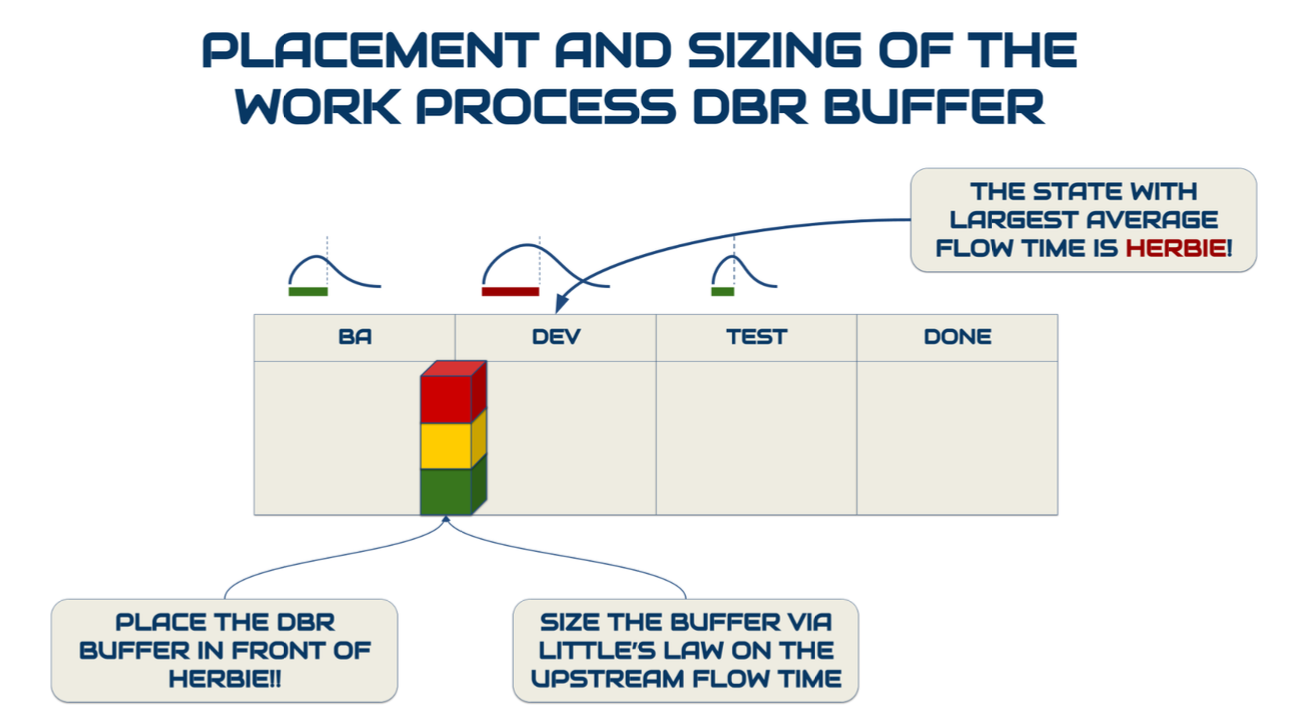
Этот буфер может иметь минимальное количество задач, но не имеет максимального. Рассчитать минимальный размер буфера можно по закону Литтла WIP = Throughput * average Flow Time предыдущих станций перед ограничением. Далее надо будет следить за состоянием буфера: если он исчерпывается, то это означает, что скоро ограничение будет простаивать, что приведет к потерям выпуска команды. Кроме того, следующая задача «на вход» в команду подаётся лишь тогда, когда ограничение взяло в работу какую-то из задач из буфера. Когда разработчики (в данном случае самая медленная станция) берут в работу задачу из бэклога, то посылается сигнал о том, что «на вход» в команду можно подать следующую задачу (обработкой которой займутся бизнес-аналитики/BA, после чего положат её в буфер). Аналитики и тестировщики могут простаивать, ожидая, пока разработчики возьмут следующую задачу, а простой разработчиков должен быть минимальным (помним, что 100% загрузки все равно не должно быть даже у ограничения).
Следующий тип буфера в TameFlow – буфер производственной мощности/capacity. Для реализации проекта требуется совместная работа нескольких команд. Для расчёта сроков и скорости выпуска нужно знать, какая команда самая загруженная (максимальная загрузка команды как рабочей станции/capacity utilization), и как лучше управлять ресурсом этой команды. Для этого мы должны проявить очередь перед каждой командой: очередь релизов, очередь спринтов или MOVEs (minimal outcome-value target, в отличие от спринта ограничивающий не время выполнения, а минимальный размер выпускаемого объекта или количество таких объектов)[6]. Далее подсчитать, сколько времени у команды займет обработать всю имеющуюся очередь. Команда, которая справится со своей очередью последней, и есть бутылочное горлышко (на уровне подразделения), а её самая медленная рабочая станция будет выступать ограничением для всего проекта[7]:
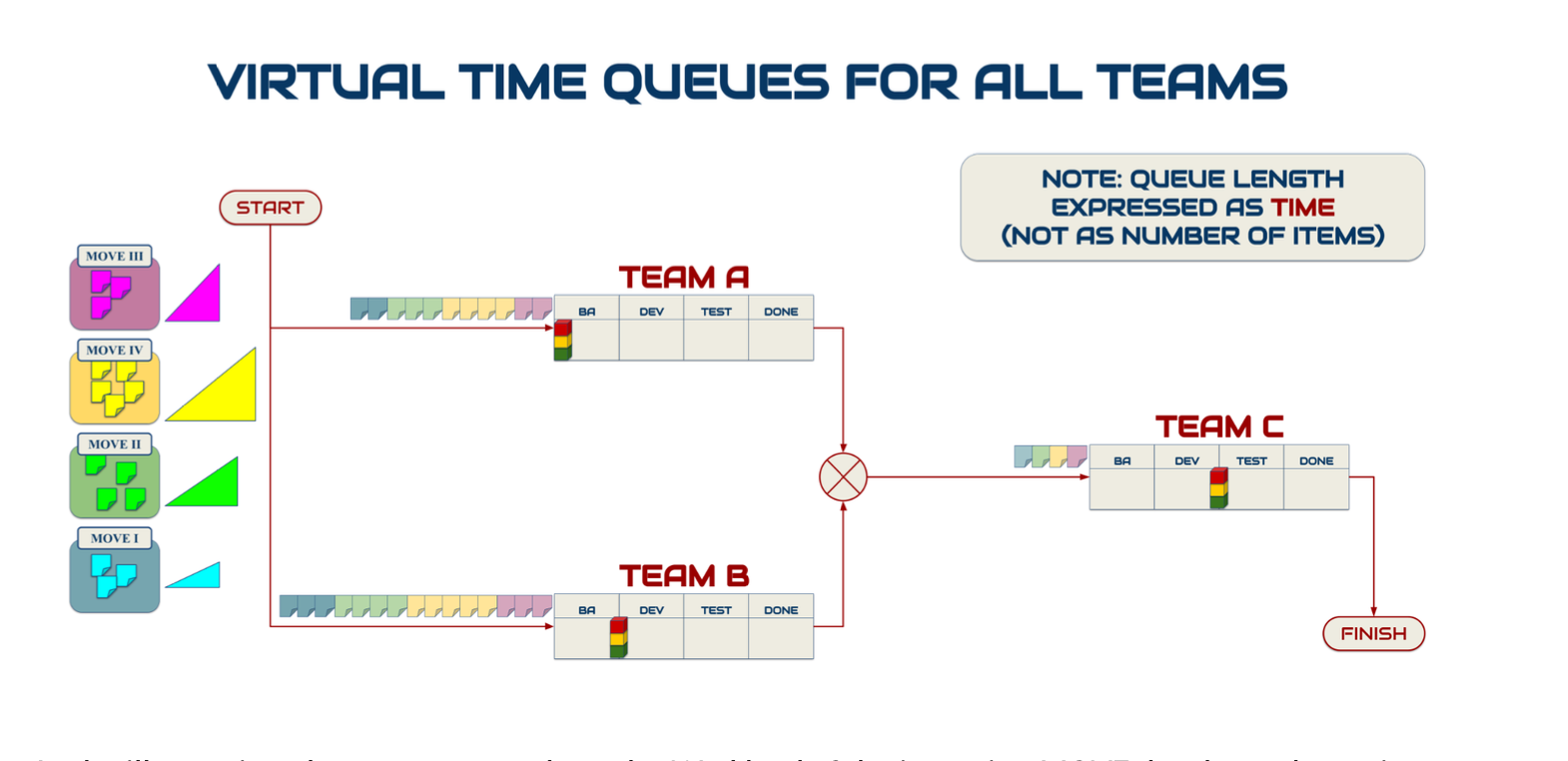
Чтобы вычислить такое ограничение, нужно будет отмоделировать (часть) конвейера, через которую пройдет реализуемый проект. То есть, нужно будет отмоделировать производственную линию с командами-рабочими станциями (см визуальное представление выше). Далее подсчитать время обработки очереди перед командой и выбрать самую медленную команду-как-рабочую станцию. Далее спуститься на уровень команды и, рассматривая команду как производственную линию, найти оргзвено/группу серверов как самую медленную рабочую станцию, ограничивающую выпуск и скорость реализации проекта. И далее все новые задачи по реализуемым в такой конфигурации проектам запускать только по сигналу «взятия новой задачи в работу» ограничением:
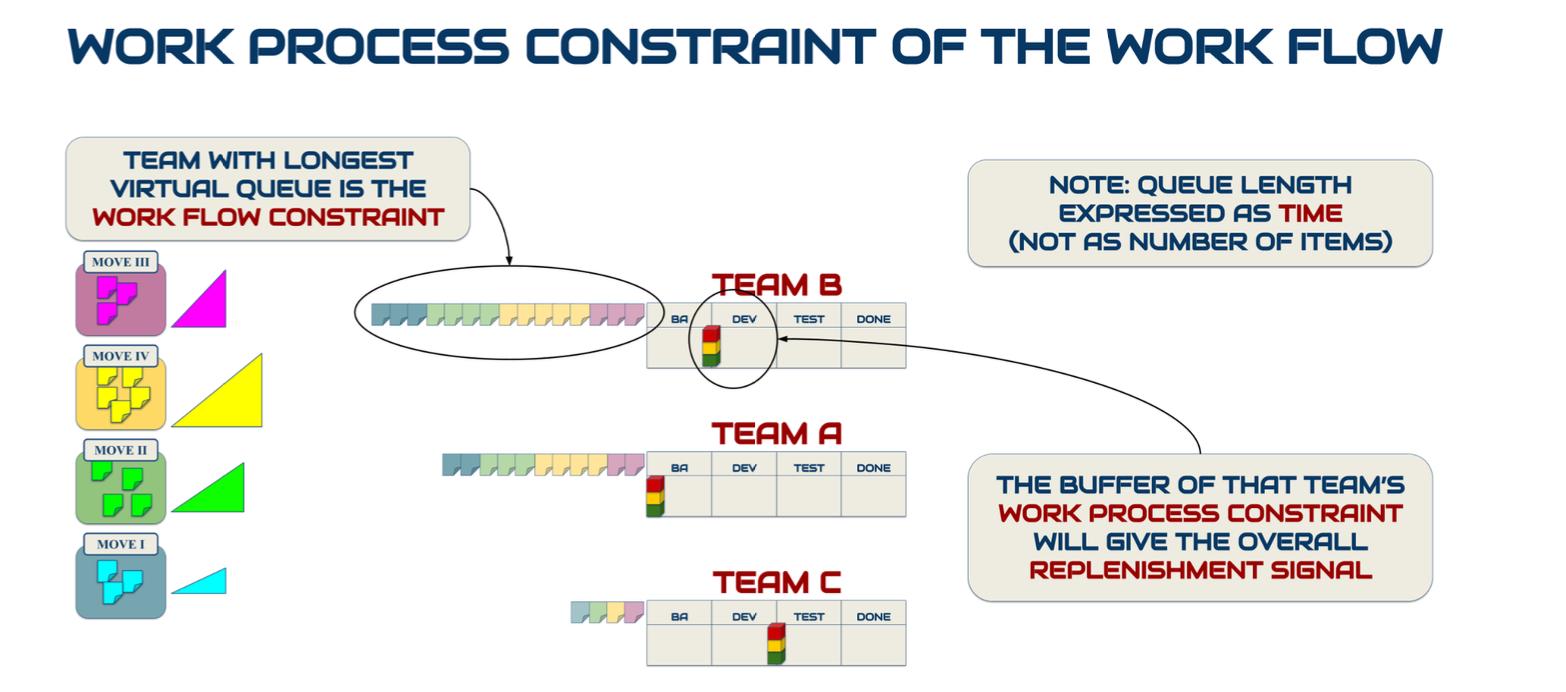
После чего можно будет последовательно выполнить каждый релиз/MOVE.
Наконец, третий тип буфера – буфер времени. В TameFlow он называется CCPM-style buffer/MOVE Buffer или буфер класса «буфер критической цепи»/буфер релиза. Его считаем так: используем имеющиеся данные об очередях (мы уже проявили очереди при помощи экзокортекса). Очереди релизов/задач на спринт/MOVE будем считать «незавершёнкой» (WIP). У нас есть данные, как быстро мы можем перерабатывать/transform/process незавершёнку такого типа (исторические данные о скорости выпуска). Мы можем спрогнозировать время выпуска, а затем рассчитать буфер. Методы расчёта подробно описаны в книге The Book of TameFlow, рекомендуется обратиться к ней. Что важно помнить при любых действиях с буфером времени: буфер закладывается в конец. Например, в случае проекта или релиза все буферное время закладывается под конец проекта или релиза, и все рабочие станции работают так, как будто этой подстраховки у них нет. Если вы планируете себе задачи в течение дня, вы можете оценить буфер на каждую задачу, но затем нужно сложить все эти буферы по времени и это общее буферное время оставить на конец дня, а планировать себе задачи так, как будто буфера нет. В случае необходимости будет поглощаться общее буферное время. Такое управление буфером времени позволяет выпускать объекты быстрее.
Можно посмотреть пример расчетов Юрия на основе данных реального проекта тут: https://t.me/systemsthinking_course/28793 ↩︎
Chapter 11 Flow Efficiency, DBR and TameFlow Boards– The Book of the TameFlow, Steve Tendon ↩︎
Чтобы в этом убедиться, рассчитайте загрузку мощностей всех рабочих станций в производственной линии и выберите станцию с наибольшей загрузкой. Станция с наибольшим средним потоковым временем и станция с наибольшей загрузкой должны совпасть. ↩︎
Если мы работаем спринтами, то мы фиксируем временной период (например, неделя), а дальше выполняем работы, которые умещаются в неделю и позволяют выпустить объект, например, релиз (он не фиксирован). Если мы работаем по MOVEs, мы фиксируем минимальный размер объекта и/или количество объектов. Например, считаем, что в следующий релиз должны войти фича №4, багфиксы №5 и №6 точно; время выполнения не фиксировано, но мы гибко учитываем дедлайны. О том, как работать при помощи MOVEs, можно прочитать в The Book of TameFlow. Работа при помощи MOVEs чуть сложнее для освоения, чем работа спринтами; но в долгосрочном периоде позволяет добиться лучших результатов, так как при работе спринтами решение самых сложных проблем всё время будет откладываться в долгий ящик, даже если они выгодны, тк решения требуют много времени. ↩︎
У этой команды также должна оказаться самая высокая загрузка ↩︎